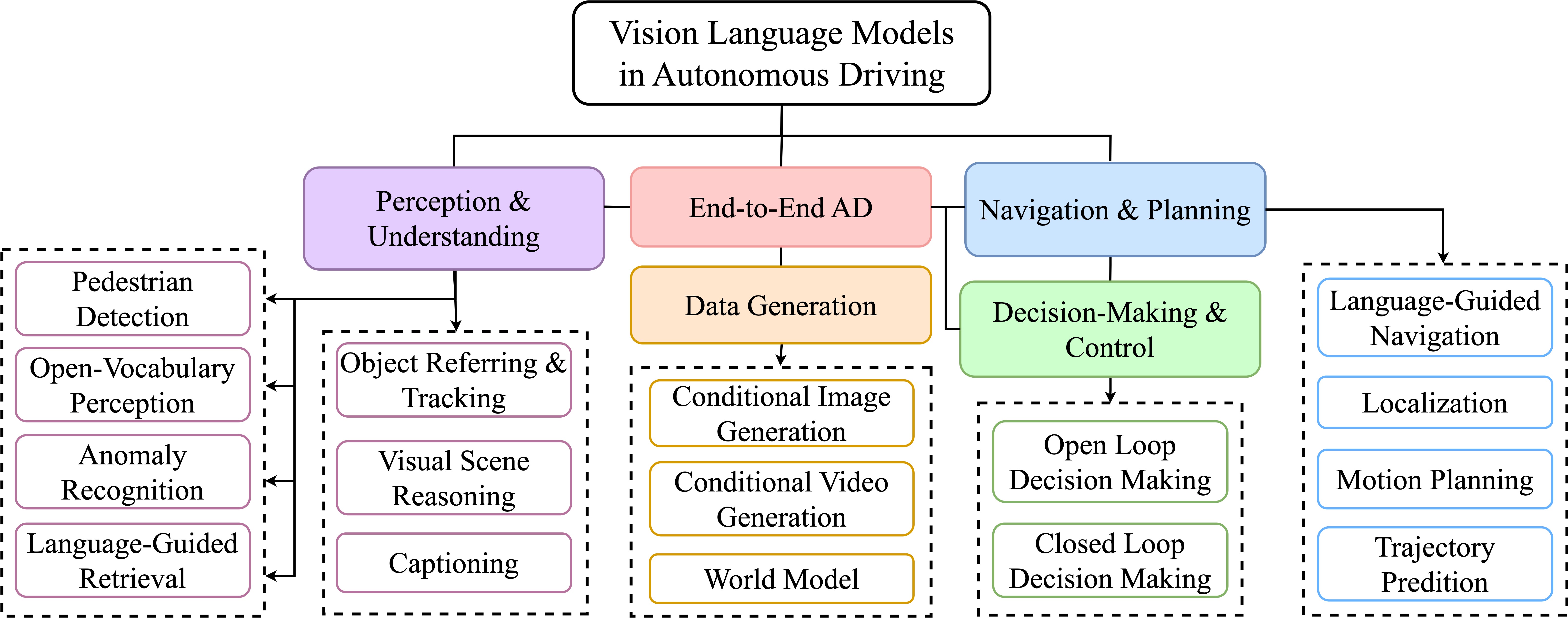
Building an VLM for ADAS Dec 14, 2025 • Chris Sunny Thaliyath Share on: <!doctype html> VLM Architecture Flow Vision-Language Model (VLM) Architecture How pixels and text merge to create understanding 1. Image Input Raw pixels (RGB) PNG/JPG 2. Vision Encoder Extracts visual features (CLIP / SigLIP / ViT) 3. Projection Layer Translates image features into "Visual Tokens" 4. User Prompt "Describe the image" TEXT 5. Tokenizer Converts words to IDs (Embeddings) 6. Multimodal Fusion Concatenation [Img Tokens] + [Txt Tokens] 7. Large Language Model (The Brain) Processes fused context & Generates Answer (Llama / Vicuna / Mistral) <Previous PostBuilding an End-to-End Autonomous Driving Stack >Blog ArchiveArchive of all previous blog posts